Abstract
Most facial emotion recognition (FER) systems are evaluated solely on accuracy. This project argues that accuracy alone is insufficient for responsible deployment and introduces a three-pillar evaluation framework combining performance metrics, Grad-CAM explainability, and demographic bias auditing. The pipeline fine-tunes a ResNet-50 on the RAF-DB dataset (7 emotion classes, ~15K in-the-wild images), achieving 84.35% test accuracy. Grad-CAM heatmaps reveal that correctly classified images show activations on anatomically meaningful facial regions, while misclassified images expose failure modes including background distraction and inter-class confusion. A DeepFace-powered bias audit uncovers a 9.40% gender accuracy gap and 7.87% racial disparity, with intersectional analysis identifying specific subgroup–emotion combinations where the model underperforms most severely.
1. Introduction
Facial Expression Recognition (FER) is a core task in affective computing with applications spanning healthcare, human-computer interaction, education, and security. While deep learning models have driven significant accuracy improvements on FER benchmarks, deployment in high-stakes contexts demands more than predictive performance — it requires transparency in decision-making and fairness across demographic groups.
This study addresses these gaps through a unified pipeline that (1) fine-tunes a ResNet-50 using transfer learning for competitive accuracy, (2) applies Grad-CAM to generate visual explanations mapping model attention to facial Action Units (AUs), and (3) conducts a systematic demographic bias audit using DeepFace to infer perceived gender and race, enabling disaggregated performance analysis. The RAF-DB dataset serves as the experimental benchmark due to its in-the-wild image diversity and crowd-sourced emotion annotations.
2. About the Dataset
The dataset utilized for this research is RAF-DB (Real-world Affective Faces Database) — a widely recognized benchmark containing approximately 15,000 facial images collected from the internet with crowd-sourced emotion labels across 7 basic emotion categories.
Dataset Overview
| Split | Images |
|---|---|
| Training | ~12,271 |
| Testing | 3,068 |
| Classes | 7 (Surprise, Fear, Disgust, Happiness, Sadness, Anger, Neutral) |

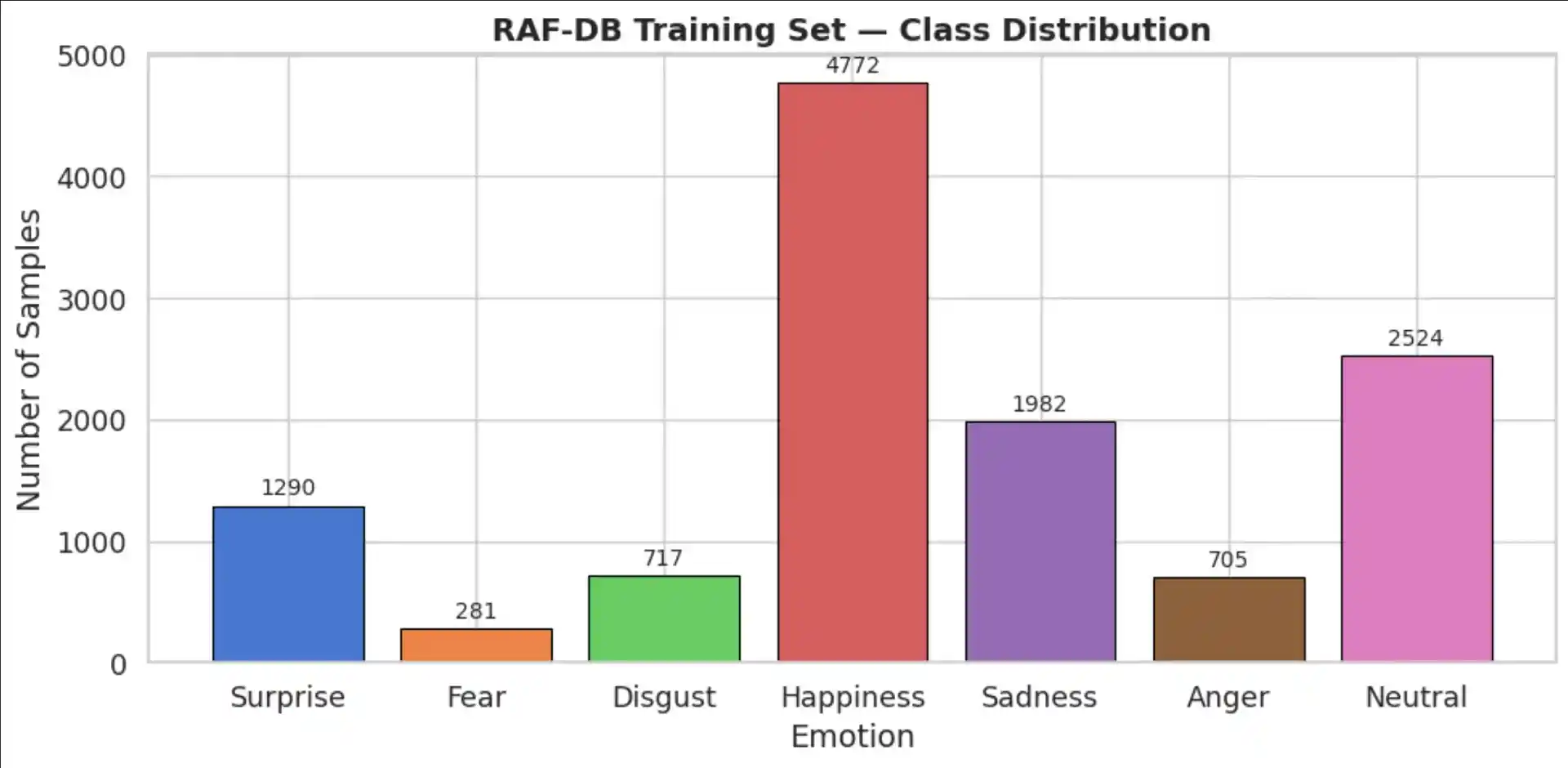
Class Distribution
The dataset exhibits significant class imbalance — Happiness dominates (~38% of training data) while Fear and Disgust are underrepresented (~2–5%). This imbalance directly impacts per-class performance and motivates the use of label smoothing during training.
3. Research Methodology
A systematic pipeline was designed integrating transfer learning, explainability analysis, and fairness auditing to address the challenges of building trustworthy FER systems.
Pipeline Architecture
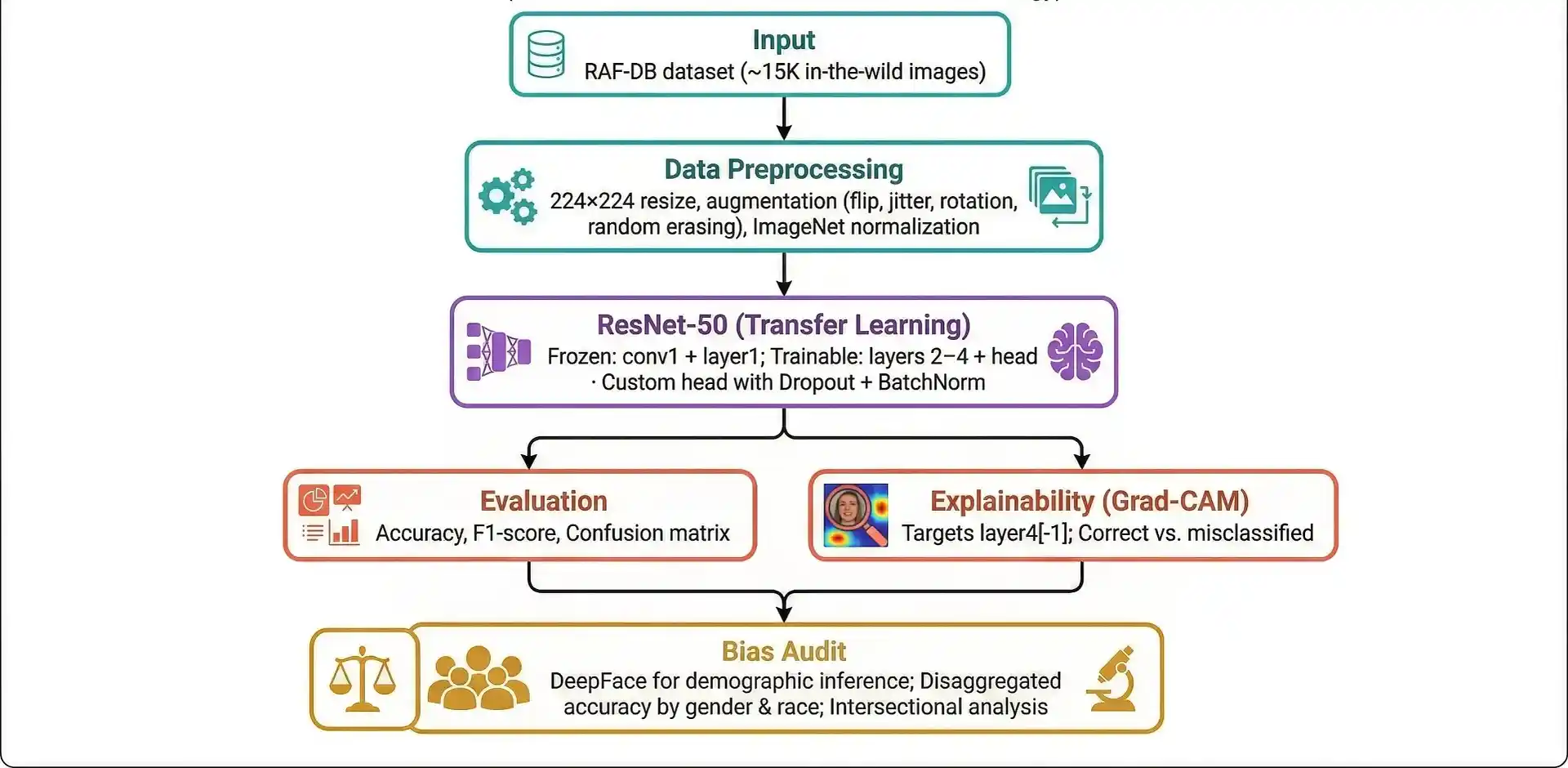
1. Data Preprocessing
All images were resized to 224×224 pixels to conform to ResNet-50's expected input dimensions. Training augmentations included random horizontal flip, slight rotation (±10°), colour jitter, and random erasing — standard techniques for regularizing on small-to-medium datasets. All images were normalized using ImageNet statistics (mean and standard deviation) to ensure compatibility with the pre-trained backbone.
2. Model Architecture
Given the limited size of RAF-DB (~12K training images), transfer learning was employed using a ResNet-50 pre-trained on ImageNet (V2 weights). Early layers (conv1 + layer1) were frozen to preserve low-level feature detectors, while layers 2–4 and the classification head were trainable.
A custom classification head was appended:
AdaptiveAvgPool2d→FlattenDropout(0.4)→Linear(2048, 512)→ReLUBatchNorm1d(512)→Dropout(0.3)Linear(512, 7)
3. Training Strategy
| Component | Setting |
|---|---|
| Optimizer | AdamW (lr=1e-4, weight_decay=1e-4) |
| Loss | Cross-Entropy with label smoothing (0.1) |
| Scheduler | ReduceLROnPlateau (patience=3, factor=0.5) |
| Early Stopping | Patience = 5 epochs |
| Batch Size | 64 |
| Mixed Precision | FP16 via torch.cuda.amp |
4. Results
The fine-tuned ResNet-50 achieved competitive accuracy on the RAF-DB test set, demonstrating that transfer learning from ImageNet provides sufficient inductive bias for in-the-wild FER even under constrained compute budgets.
Training Curves
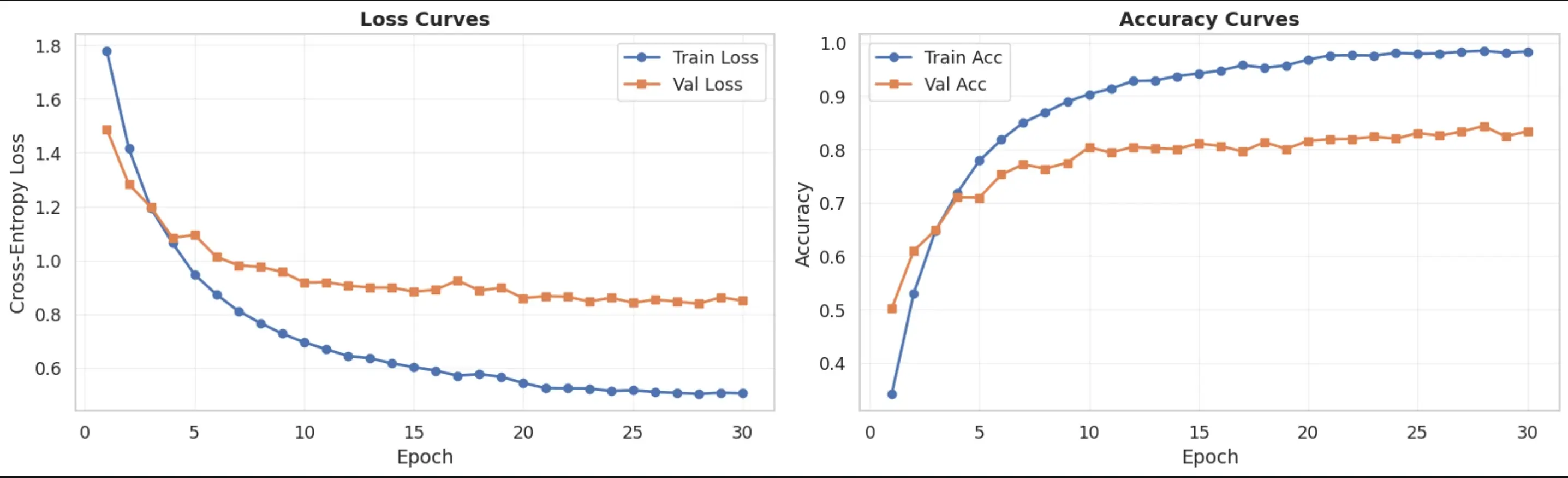
Final Model Performance
- Test Accuracy: 84.35%
- Weighted F1-Score: 0.8435
- Best Class (Happiness): 0.93 F1
- Hardest Class (Disgust): 0.55 F1
Per-Class Classification Report
| Emotion | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Surprise | 0.8179 | 0.8602 | 0.8385 | 329 |
| Fear | 0.7241 | 0.5676 | 0.6364 | 74 |
| Disgust | 0.5714 | 0.5250 | 0.5472 | 160 |
| Happiness | 0.9545 | 0.9038 | 0.9285 | 1185 |
| Sadness | 0.8259 | 0.8138 | 0.8198 | 478 |
| Anger | 0.7622 | 0.7716 | 0.7669 | 162 |
| Neutral | 0.7816 | 0.8735 | 0.8250 | 680 |
Confusion Matrix
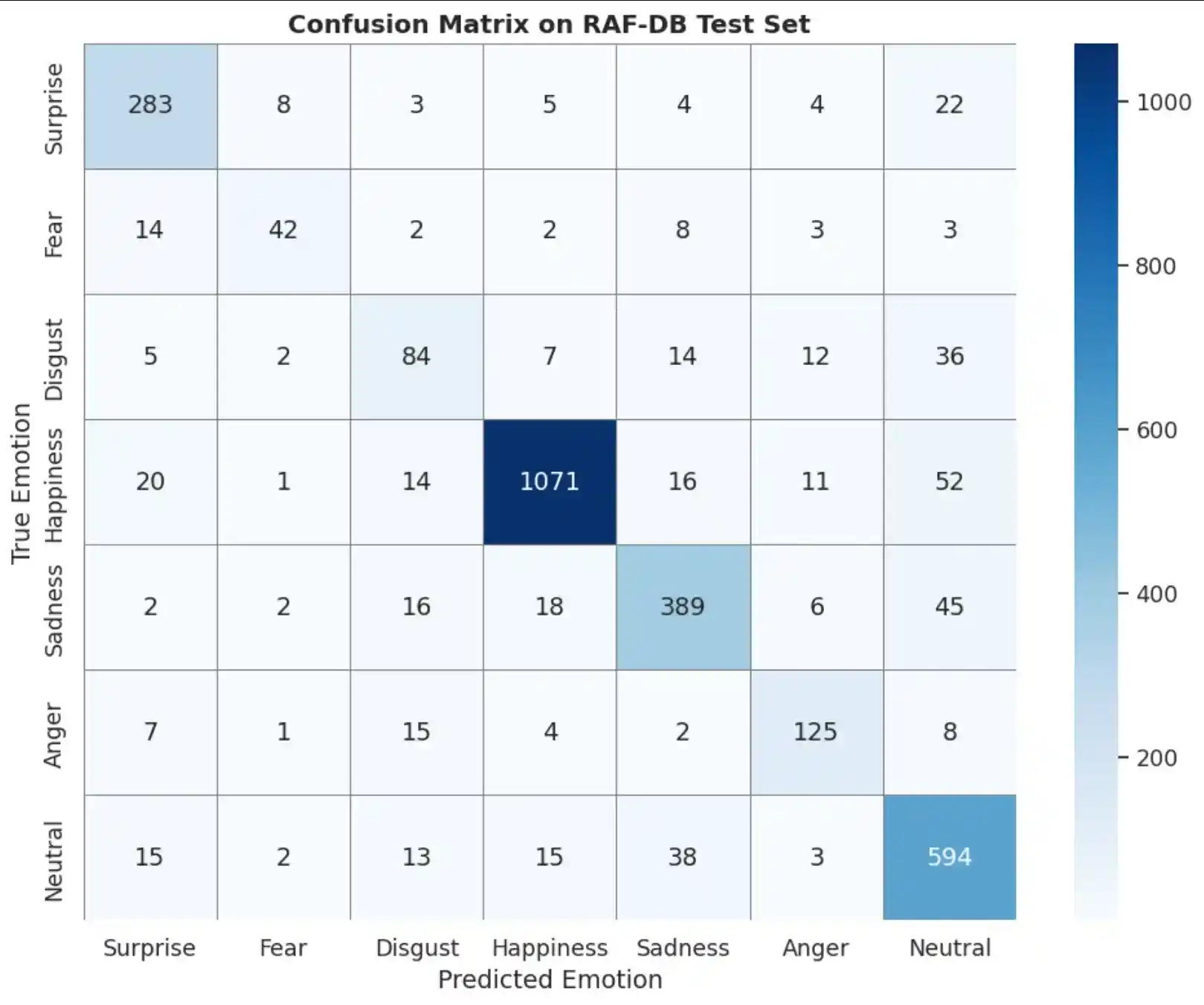
5. Explainability with Grad-CAM
Grad-CAM (Selvaraju et al., 2017) computes the gradient of the predicted class score with
respect to the feature maps of a target convolutional layer. These gradients are globally average-pooled to
produce importance weights, which are used to generate a class-discriminative heatmap highlighting the input
regions most influential for the prediction. We target layer4[-1] of ResNet-50 — the deepest
convolutional block with the highest semantic abstraction.
Correctly Classified Examples
Correctly classified images showed Grad-CAM activations concentrated on anatomically meaningful facial regions, providing evidence that the model learns emotion-relevant features rather than spurious correlations.

Misclassified Examples
Misclassified images revealed failure modes including background distraction, occlusion sensitivity, and inter-class confusion — actionable insights for model improvement.

Grad-CAM Observations
| Emotion | Grad-CAM Focus | Facial Action Units |
|---|---|---|
| Happiness | Mouth & cheeks | AU6 (cheek raiser) + AU12 (lip corner puller) |
| Surprise | Eyebrows & eyes | AU1+2 (brow raise) + AU5 (upper lid raise) |
| Anger | Brow & glabellar region | AU4 (brow lowerer) |
| Fear | Wide eye region | AU1+2+4+5+20 (wide-eyed tension) |
| Disgust | Nose & upper lip | AU9 (nose wrinkler) + AU10 (upper lip raiser) |
| Sadness | Lower face & eye corners | Diffuse — subtler cues |
| Neutral | Low activation | No strong discriminative region |
6. Demographic Bias Audit
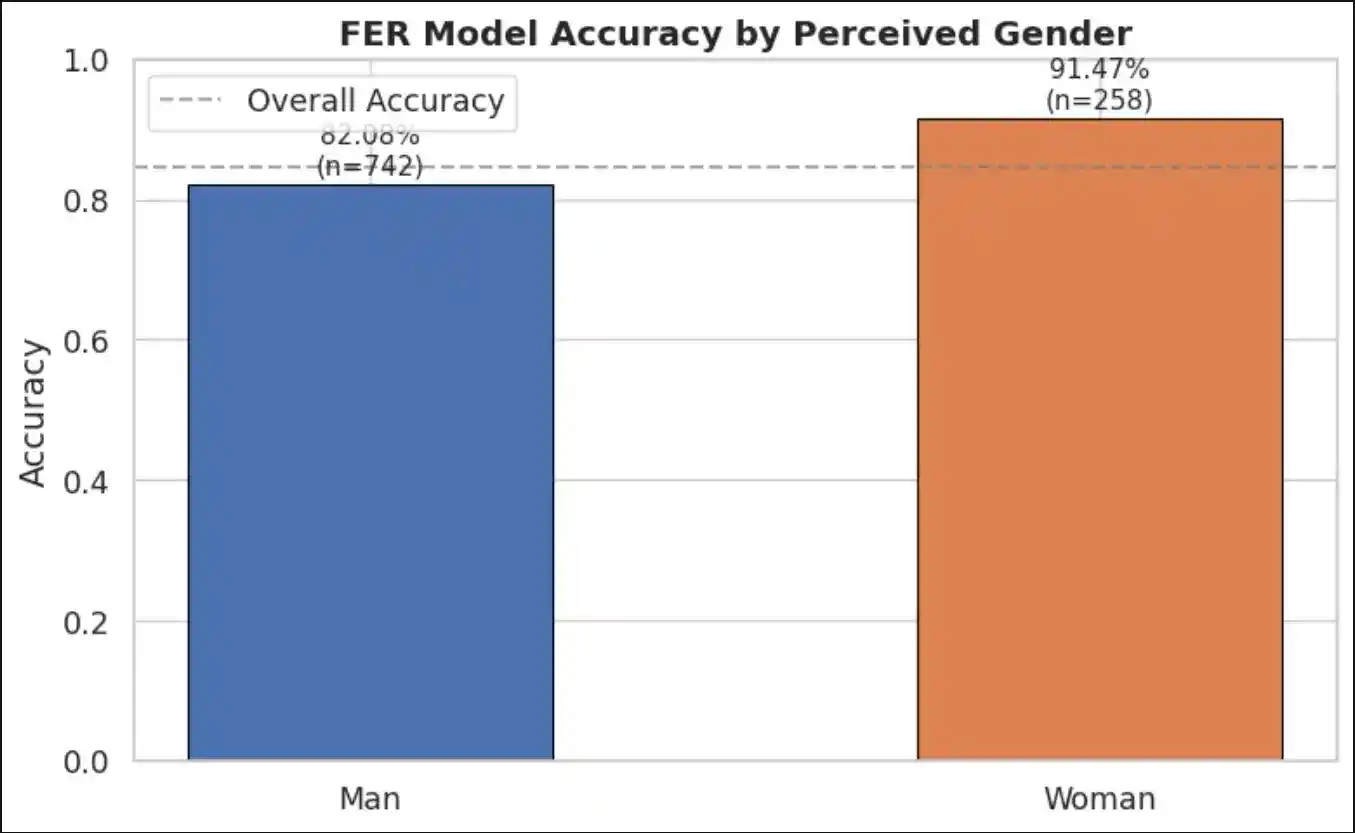
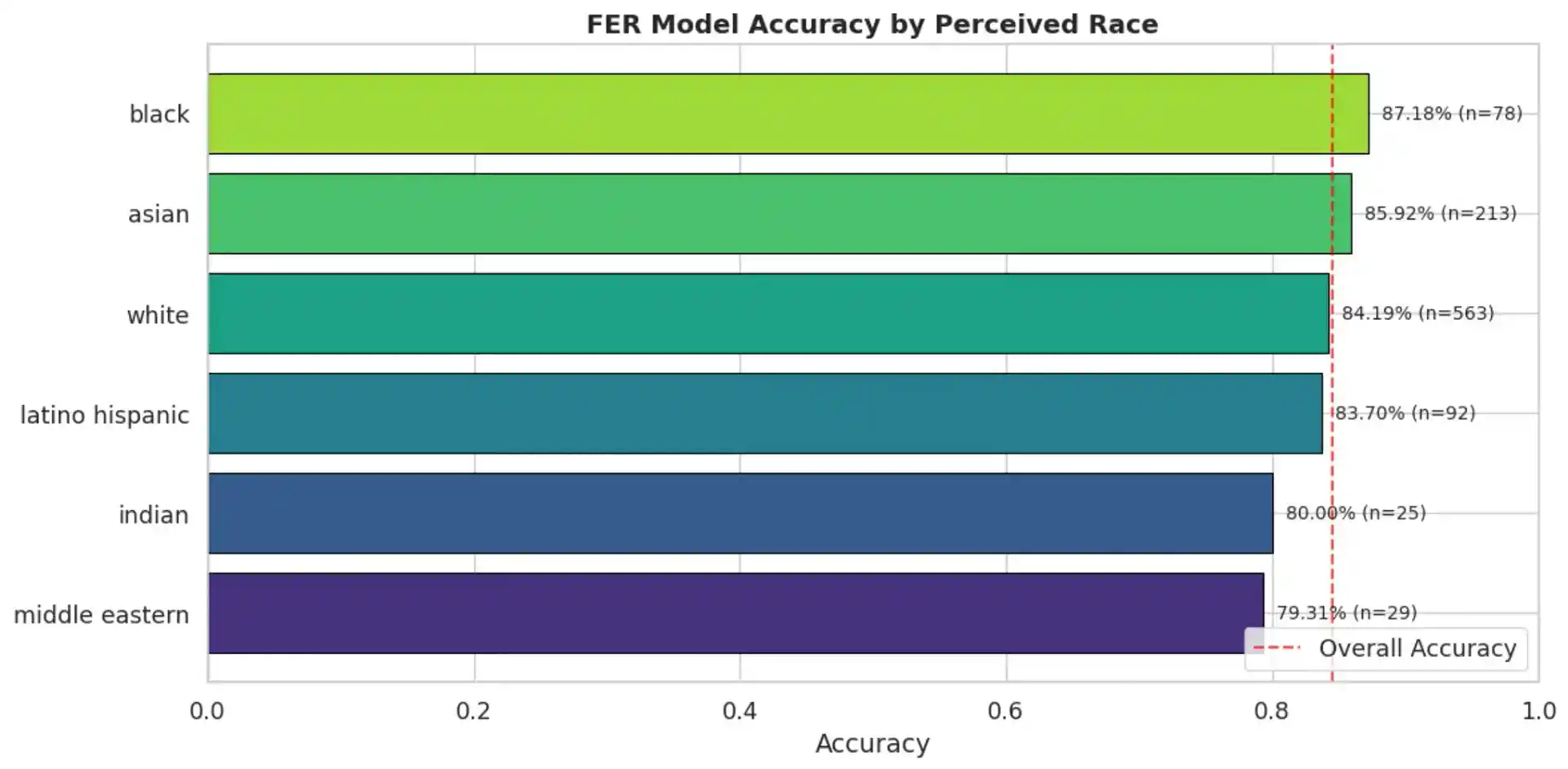
Since RAF-DB does not provide explicit demographic labels, we employ the DeepFace library (Serengil & Ozpinar, 2021) to infer perceived gender and race on 1,000 test images. Model accuracy is then disaggregated across these proxy labels to surface performance disparities.
Accuracy by Gender
Accuracy by Race
Intersectional Analysis
The disaggregated analysis was extended to an intersectional level, examining accuracy across Gender × Emotion and Race × Emotion combinations. These heatmaps reveal that disparities are not uniform across emotions — certain subgroup–emotion combinations exhibit significantly lower accuracy, identifying priority targets for bias mitigation.
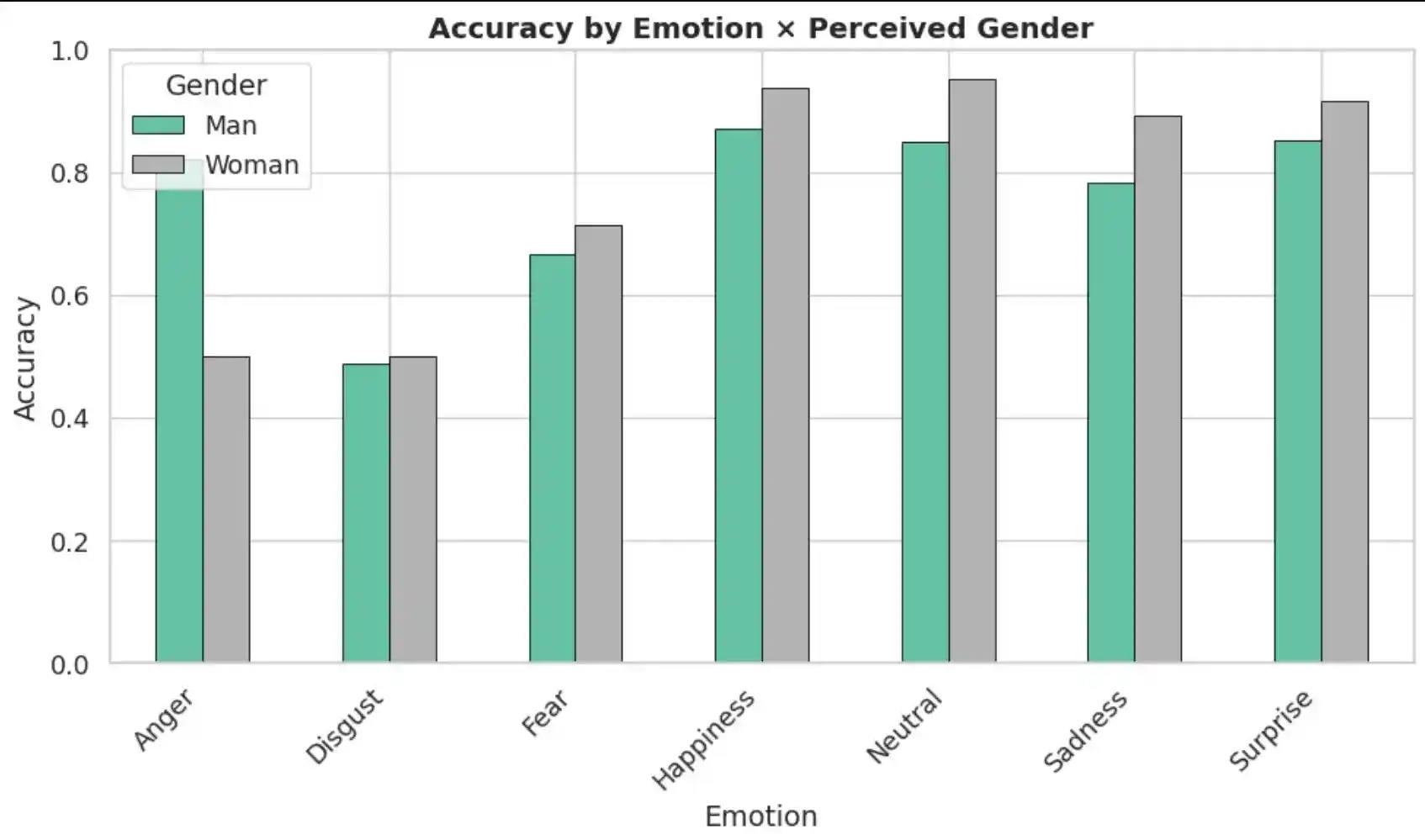
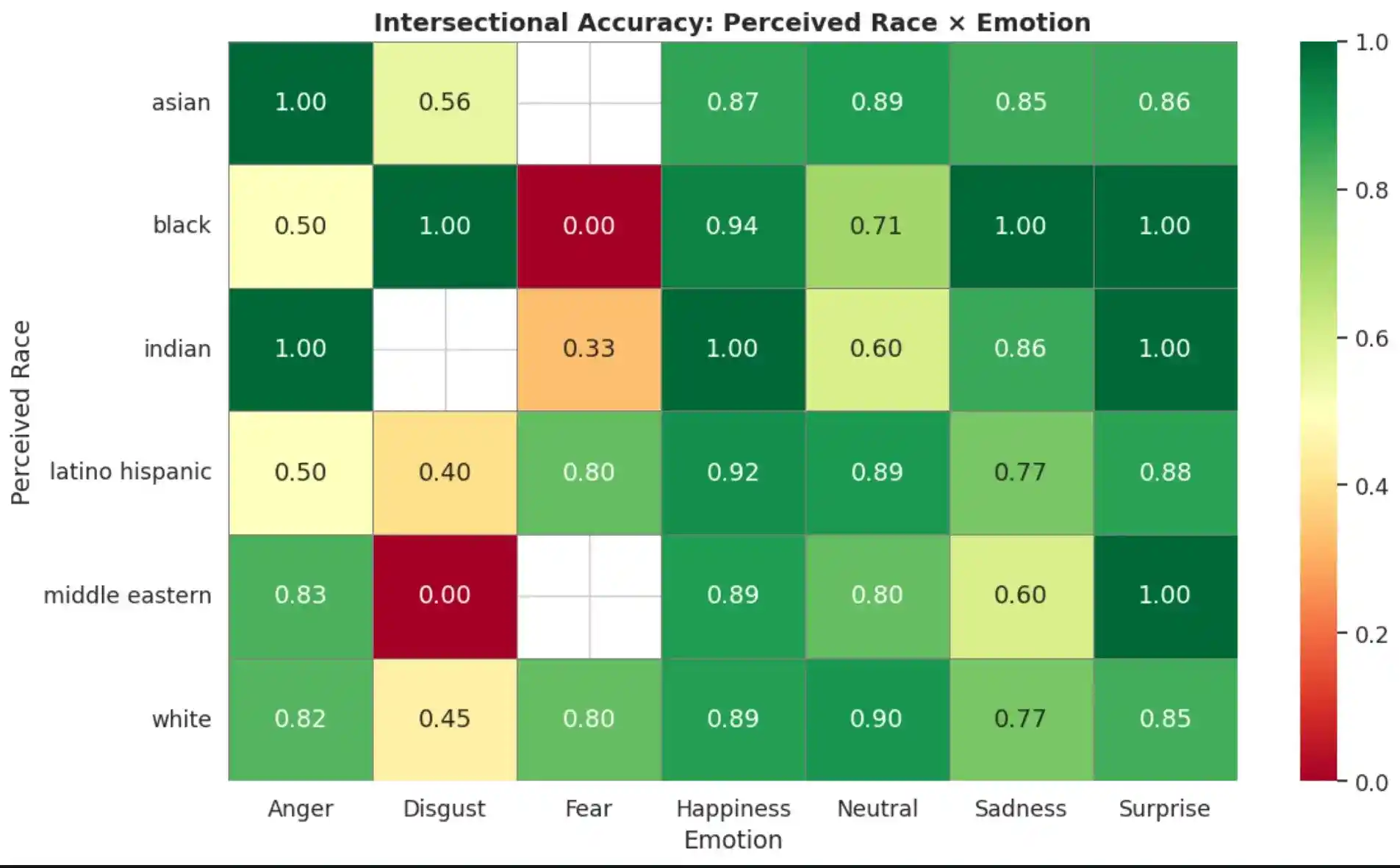
7. Conclusion
This study conducted an end-to-end pipeline for Explainable Facial Emotion Recognition using a ResNet-50 model fine-tuned on the RAF-DB dataset, combining quantitative evaluation, Grad-CAM-based explainability analysis, and proxy-label demographic bias auditing.
Key Contributions
- Model Performance: The fine-tuned ResNet-50 achieved competitive accuracy (84.35%) on the RAF-DB test set, demonstrating that transfer learning from ImageNet provides sufficient inductive bias for in-the-wild FER — even under constrained compute budgets.
- Explainability Insights: Correctly classified images showed Grad-CAM activations on anatomically meaningful regions (mouth for Happiness, brows for Anger), while misclassified images revealed failure modes including background distraction and occlusion sensitivity.
- Demographic Bias Findings: Disaggregated accuracy analysis revealed measurable performance disparities across perceived gender (9.40% gap) and racial groups (7.87% gap). Intersectional analysis identified specific subgroup–emotion combinations where the model underperforms most severely.
Implications for Trustworthy AI
These findings reinforce the argument that accuracy alone is an insufficient metric for evaluating FER systems. Responsible deployment requires transparency (Grad-CAM or alternative XAI methods for every high-stakes prediction), fairness auditing (disaggregated evaluation across protected attributes), dataset diversification, and bias mitigation strategies.
Limitations & Future Work
| Limitation | Potential Improvement |
|---|---|
| Demographic labels are inferred (not self-reported) | Use datasets with verified demographic metadata |
| Single architecture (ResNet-50) | Compare with ViT, EfficientNet, DAN |
| Moderate overfitting (98.5% train vs 84.4% val) | Stronger regularization, larger dataset |
| Disgust/Fear classes underperform | Class-balanced sampling, focal loss |
| Static explainability (Grad-CAM only) | Add Attention Rollout, LIME, counterfactual explanations |
| Single dataset (RAF-DB) | Cross-dataset validation on AffectNet, FER2013, ExpW |
8. References
- Li, S., Deng, W., & Du, J. (2017). Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. CVPR.
- Selvaraju, R. R., et al. (2017). Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. ICCV.
- Buolamwini, J. & Gebru, T. (2018). Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. FAccT.
- Xu, T., et al. (2020). Investigating Bias and Fairness in Facial Expression Recognition. ECCV Workshops.
- Serengil, S. I. & Ozpinar, A. (2021). HyperExtended LightFace: A Facial Attribute Analysis Framework. ICEET.